分类 · 框架
智能体应用安全指南V1.0
OWASP的智能体安全指南框架解读
目录
-
智能体安全框架
-
全生命周期安全开发指南
-
智能体安全最佳实践
-
智能体操作能力安全控制
-
智能体供应链安全
-
智能体安全评测基准
-
智能体部署安全
-
智能体运行安全
** **
智能体安全框架
智能体六大关键组件
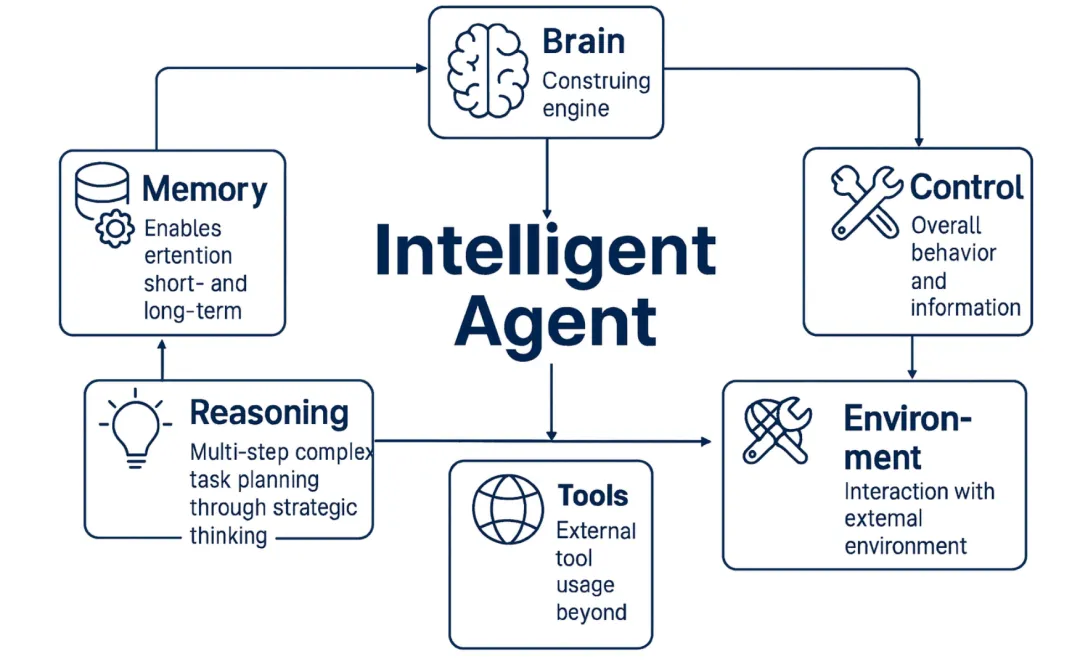
- 生成式语言模型(Brain):智能体的“脑”(认知引擎),负责理解、推理、规划和生成响应。例如,GPT-4、Claude等大型语言模型(LLM),通常基于预训练的基础模型,这些模型提供广泛的知识,可以通过提示工程或微调等技术进行专业化。
| 类别 | 说明 |
|---|---|
| 大型语言模型(LLMs) | 核心认知引擎(“大脑”),利用预训练的基础模型(如GPT系列、Claude系列、Llama系列、Gemini系列)进行推理、规划和生成,主要通过提示工程进行引导,并在上下文窗口、延迟和成本等限制条件下操作。 |
| 多模态语言模型(MLLMs) | 能够处理和/或生成多种数据类型的信息的LLM,超越文本(例如,图像、音频),使智能体能够执行涉及视觉或听觉信息的更广泛任务(例如,GPT-4V、Gemini)。 |
| 小模型(SLMs) | 参数较少的语言模型,通常在较小、更专注的数据集上进行训练。SLMs通常设计用于执行特定任务或在特定用例中工作,而不像LLM那样具有广泛的通用能力。与LLM相比,SLM的特点是较小的权重空间、参数大小和上下文窗口。 |
| 微调模型 | 对语言模型(LLM / MLLM)进行额外训练以专门化其能力,提升性能、采用个性化或提高可靠性,以满足智能体要求的特定任务、领域或交互风格。例如,监督式微调(SFT)和断路器(CB)已被发现可以带来有前景的范围控制益处,减少智能体提供超出范围话题答案的倾向。 |
- 编排(Control):控制智能体的整体行为、信息流和决策过程。具体机制(例如,对于分层架构使用“顺序”,对于黑板架构使用“动态”,或者对于多智能体系统使用“协调”)取决于架构,并影响智能体的响应能力和效率。
| 类别 | 说明 |
|---|---|
| 工作流程 | 智能体为了实现目标而遵循的有序、预定义的任务或步骤序列。 |
| 分层规划 | 多个智能体通过调度器(路由器)进行协作。 |
| 多智能体协作 | 智能体可以进行通信并协调他们的行动,共享信息和资源。 |
- 推理规划范式(Reasoning):智能体利用大型语言模型(LLMs)解决需要多步骤的复杂任务,通过战略性思维进行规划。为此,智能体将高层任务分解为更小的任务(步骤),每个步骤具有不同的子目标。
| 类别 | 说明 |
|---|---|
| 结构化规划/执行 | 将任务分解为正式计划,定义动作序列,通常涉及特定的工具调用。 |
| 动态推理反馈 | 动态地交错推理步骤和动作(例如使用工具或查询API),并根据反馈更新推理。 |
| 思维链(CoT) | 通过逐步“思考”提示来提高推理质量,引导大语言模型在得出最终行动或结论之前生成一系列“想法”。 |
| 思维树(ToT) | 通过探索多个推理路径和计划,同时使用前瞻、回溯和自我评估来推广 CoT。 |
- 内存模块(Memory):使智能体能够保留短期(即时上下文)和长期信息(过去的互动、知识),以便进行连贯和个性化的互动。通过使用上下文“敏感性”(分类或隔离),降低未经授权的信息暴露风险。使用带有向量数据库的检索增强生成(RAG)常用于长期记忆,允许智能体通过语义搜索检索并整合外部知识。
| 类别 | 说明 |
|---|---|
| 在智能体会话内存 | 内存仅限于单个智能体和单个会话,这限制了如果被攻破时危及其他智能体/会话的能力。 |
| 跨智能体会话内存 | 内存在多个智能体之间共享,但仅限于单个会话,限制了攻破其他会话的能力,但如果一个智能体被攻破,可能会危及同一会话下的多个智能体。 |
| 在智能体跨会话内存 | 内存仅限于单个智能体,但跨多个会话共享,限制了攻破其他智能体的能力,但一个被攻破的会话仍然可能导致多个会话的安全问题。 |
| 跨智能体跨会话内存 | 内存在多个智能体和会话之间共享。如果一个智能体在特定会话中被攻破,它可能会危及其他会话和/或智能体。 |
| 在智能体跨用户内存 | 内存仅限于单个智能体,但跨多个用户共享。被攻破的智能体可能会有能力危及多个用户。 |
| 跨智能体跨用户内存 | 内存在多个智能体和用户之间共享。被攻破的智能体可能会有能力危及其他智能体和用户。 |
- 工具集成框架(Tools):允许智能体通过使用外部工具(如API、函数、数据存储)超越文本交互,向现实世界或其他系统进行交互。工具集成框架用于管理这些工具的选择和使用。这些框架提供了各种“智能体”类型,例如ReAct、Self-Ask和OpenAI Functions Agent。
| 类别 | 说明 |
|---|---|
| 灵活库/SDK特性 | 这些提供了代码级的构建块(例如LangChain、AG2、Agents、CrewAI、MCP)或特定的API功能(如OpenAI的工具使用功能),供开发者使用。它们提供高度的灵活性和对智能体行为及工具编排的控制,但需要更多的编码工作和技术专长来实现和管理完整的智能体循环。 |
| 管理平台/服务 | 这些是供应商提供的解决方案(如Amazon Bedrock Agents,Microsoft Copilot Platform),它们处理基础设施、简化设置并管理构建带有工具的智能体的很多编排工作。它们通常在供应商的生态系统中提供更容易的集成,并且可能包括低代码接口,牺牲一些灵活性以换取更快的开发和部署。 |
| 托管API | 与托管平台类似,但通常强调API作为主要的交互点,这些是供应商托管的服务(如OpenAI的Assistants API),提供更高层次的抽象。通过API调用,它们管理状态和工具编排的复杂性,相比仅使用基础SDK特性,它们使得构建复杂的、有状态的智能体变得更加容易。 |
- 操作环境(Environment):尽管大型语言模型(LLMs)仅限于它们最后训练更新时可用的数据,智能体可以通过工具和函数调用与外部环境进行接口。利用不同的智能体使其能够与外部环境交互,收集和处理来自外部环境的信息,从而使其能够有效地在这些环境中操作。
| 类别 | 说明 |
|---|---|
| API访问 | 智能体利用LLM的能力生成预定义API调用的一些参数或者生成整个API调用 |
| 代码执行 | 智能体利用LLM的能力生成预定义函数的一些参数或者直接运行LLM生成的代码 |
| 数据库执行 | 智能体利用LLM的能力针对数据库运行特定查询或命令;利用LLM的能力生成并执行所有CRUD操作,针对一组表或整个数据库;利用外部数据源获得上下文信息,或根据用户输入更新外部源中的记录 |
| Web访问能力(网页访问) | 智能体利用LLM与浏览器操作(例如,OpenAI操作员,网页使用)。被攻破的智能体可能由于暴露于不信任的网页内容而形成,它可能通过利用智能体的过度授权代表用户执行不必要的操作(例如,改变共享设置或开放用户会话的账户设置)。 |
| 控制PC操作(PC使用) | 智能体利用LLM操作操作系统,包括文件系统(例如,Anthropic计算机使用)。被攻破的智能体可能执行不必要的操作,暴露或泄露个人信息,并执行恶意操作,如加密文件。 |
| 操作关键系统(例如SCADA) | 智能体利用LLM操作关键系统。关键系统中的未经授权操作可能导致灾难性故障。被攻破的智能体可能会导致系统操作严重中断。 |
| 物联网设备访问权限 | 对物联网设备的未经授权控制。被攻破的智能体可能影响托管这些物联网设备的操作环境,可能以恶意或非预期的方式利用它们(例如,使用物联网连接的温控器大幅改变房间温度)。 |
智能体攻击面分析
 ’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
| 关键组件 | 相关威胁 | 风险描述 |
|---|---|---|
| KC1 - 大型语言模型(LLMs) | T5, T6, T7, T15 | 代理的“脑”中的核心漏洞:幻觉、目标不一致、欺骗性推理以及对人类的操控。 |
| KC2 - 编排(控制流) | T6, T8, T9, T10, T12, T13, T14 | 工作流控制中的漏洞:目标操控、缺乏审计能力、身份混淆、超载人类监督和多代理攻击。 |
| KC3 - 推理/规划范式 | T5, T6, T7, T8, T15 | 决策过程中的弱点:级联幻觉、意图操控、欺骗性推理、无法追溯的决策和人类操控。 |
| KC4 - 内存模块 | T1, T3, T5, T6, T8, T12 | 数据完整性问题:内存中毒、数据泄露、幻觉传播、证据篡改和通信中毒。 |
| KC5 - 工具集成框架 | T2, T3, T6, T8, T11 | 工具滥用漏洞:工具滥用、权限提升、未记录的操作和意外的代码执行。 |
| KC6 - 操作环境 | T2, T3, T4, T10, T11, T12, T13, T15 | 监控漏洞和外部系统风险:滥用访问、权限妥协、资源消耗、超载人工审查、代码执行攻击、旁路信息存储/通信以及通过环境的操控。 |
相关威胁参考智能体15个安全威胁及其防护措施(OWASP,2025),每个关键组件的详细攻击面见底部阅读原文。
全生命周期安全开发指南
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
设计与开发阶段
代理型AI系统需要的不仅仅是对LLM(大语言模型)核心安全风险的缓解措施,还涉及全新安全面临的风险。这些风险包括:持久内存引发的上下文污染、数据泄露和未授权状态保留;自主规划引发的目标不一致、递归决策循环和不可预测的突现行为。设计阶段必须考虑这些风险,包括定义“安全失败”状态、划定集成边界、指定内存访问政策并确保必要的人类干预。
| 子项 | 目标 | 实践方法 |
|---|---|---|
| 代理系统威胁建模 | 分析代理系统的潜在威胁模型 | 查看最新的代理AI威胁和缓解措施智能体15个安全威胁及其防护措施(OWASP,2025) |
| 系统提示工程与加固 | 定义代理的核心指令、功能和限制,防止被操控或行为异常 | 1. 明确边界与保护措施2. 抵御注入攻击3. 清晰角色定义4. 最小化微调 |
| 安全编码实践 | 实施适用于AI代理开发的安全编码原则 | 1. 输入验证2. 错误处理3. 安全密钥管理4. 最小权限 |
| 内容审核集成设计 | 设计早期检测与过滤有害或违反政策的内容 | 1. 识别必要的检查项2. 评估工具(如基于规则的过滤器、机器学习分类器) |
| 人类干预设计 | 确定在代理执行高风险操作前需要的人类干预 | 1. 风险识别2. 清晰工作流3. 框架集成 |
| 内存保护设计 | 防止未经授权的访问、篡改和数据泄露 | 1. 访问控制2. 加密存储与传输数据3. PII数据处理4. 人类干预 |
| 输入/输出验证与净化设计 | 确保代理数据的完整性与安全性,避免暴露多余数据 | 1. 输入净化2. 输出净化3. 使用结构化格式4. 使用允许与拒绝列表 |
| 授权与认证 | 确保代理系统的身份认证与授权,确保系统安全性 | 1. 使用身份提供商与授权服务器2. 分配去中心化标识符(DID) |
构建与部署阶段
在将代理型应用投入生产时,开发生命周期需要具备强大和适应性强的保障。开发环境应该采用沙箱隔离技术,部署流水线不仅仅局限于打包发布,还需包括清晰标注的代理能力快照、日志记录以及签名约束。
| 子项 | 目标 | 实践方法 |
|---|---|---|
| 静态分析与代码扫描(SAST) | 自动检测代理源代码中的潜在安全漏洞 | 1. 集成SAST工具进CI/CD管道,2. 关注常见的Web漏洞、API不安全使用等。 |
| 依赖性漏洞扫描(SCA) | 识别代理所使用的第三方库和依赖中的已知漏洞 | 1. 将SCA工具集成至CI/CD管道,2. 定期扫描并更新库文件。 |
| 环境加固与沙箱化 | 隔离代理的执行环境,限制潜在攻击的影响 | 1. 限制部署流水线访问,2. 使用沙箱技术如Docker、VM或WebAssembly进行环境隔离。 |
| 安全配置管理 | 确保在部署过程中安全管理配置,特别是密钥与API的管理 | 1. 使用专门的密钥管理系统(如AWS Secrets Manager),2. API访问控制。 |
| 预部署测试(模糊测试,渗透测试) | 在发布前主动测试代理及其接口的漏洞 | 1. 使用自动化工具进行提示接口模糊测试,2. 定期进行渗透测试。 |
| 运行时安全与内存隔离 | 提供深层防御,即使底层LLM存在漏洞也能确保安全 | 1. 使用静态API/方法,2. 隔离不可信数据与执行流。 |
操作与运行阶段
代理型系统需要持续的行为监控,监控不仅限于性能,还需涵盖决策过程、计划演化、内存访问模式和工具交互等。监控应能够识别行为漂移,及时触发警报或采取防护措施。
| 子项 | 目标 | 实践方法 |
|---|---|---|
| 持续监控与异常检测 | 实时检测恶意活动、政策违规和行为偏差 | 1. 扫描LLM输入输出2. 监控工具调用3. 观察计划执行4. 内存异常检测 |
| 运行时防护与自动审核 | 动态执行策略与约束,以确保代理操作符合规定 | 1. 输入/输出防护2. 内容过滤3. 内存TTL管理4. 界面安全显示 |
| 日志记录、审计与可追溯性 | 支持调试、安全分析、合规性检查,记录详细的代理行为 | 1. 集中日志平台2. 使用结构化日志(如JSON)3. 追溯ID传递 |
| 漏洞扫描(运行时) | 持续扫描运行中的应用及环境中的新漏洞 | 1. 定期进行基础设施漏洞扫描2. 集成DAST扫描工具(如OWASP ZAP) |
| 事件响应计划 | 确定AI代理相关的安全事件,并提前制定响应计划 | 1. 定义事件的标准2. 明确响应流程3. 定期进行演练和“火灾”演习 |
漏洞扫描(运行时)
| 子项 | 目标 | 实践方法 |
|---|---|---|
| 漏洞扫描 | 持续扫描运行中的应用和环境中的新漏洞 | 定期进行基础设施漏洞扫描。 |
| 补丁管理 | 将漏洞扫描结果集成到补丁管理流程中 | 将扫描结果整合进补丁管理流程,以便及时修复漏洞。 |
| DAST扫描 | 使用动态应用安全测试扫描API和接口 | 在较低环境中使用DAST扫描,如OWASP ZAP,检查API和常见接口。 |
| 端口和CVE扫描 | 检查环境端点的安全性 | 使用端口扫描和CVE扫描器对环境端点进行安全性检测。 |
事件响应机制
| 子项 | 目标 | 实践方法 |
|---|---|---|
| 事件定义 | 定义什么构成安全事件 | 例如,成功的提示注入导致危害、数据泄露、代理执行未经授权的操作。 |
| 应急响应步骤 | 规划事件应急响应步骤 | 1. 遏制(禁用代理、限制工具访问)2. 分析(使用日志和监控数据)3. 修复和报告 |
| 角色与责任分配 | 明确各方在事件响应中的角色和责任 | 分配响应各个阶段的责任,并确保角色分配清晰。 |
| 事件响应演练 | 定期进行演练测试响应计划 | 使用桌面演练和模拟“火灾”演习来测试响应计划。 |
AI 机器人缓解与控制
随着AI代理的逐步发展,特别是在高影响力任务中的应用,防止恶意行为的机器人身份伪造变得尤为重要。通过创建不可篡改的AI代理身份层,能够确保每次代理行为的验证和可追溯性,从而有效防止机器人滥用和恶意操作。
| 子项 | 目标 | 实践方法 |
|---|---|---|
| 身份验证 | 防止身份伪造及机器人滥用 | 1. 确保代理身份经过验证,2. 每个请求需进行身份验证,避免伪造身份的攻击。 |
| 多因素身份验证 | 使用多种身份验证信号确保代理身份的可信度 | 使用多因素身份验证,例如生物识别、证书、签名等多种方法。 |
| 权限控制 | 确保代理仅执行被授权的操作,防止滥用或非法操作 | 对每个请求实施权限检查,确保只有被授权的操作被执行。 |
| 风险防范与滥用检测 | 通过防滥用机制防止机器人进行数据盗取、欺诈或注入恶意命令 | 实施智能检测算法,及时识别并响应异常行为。 |
| 代理行为审计 | 提供代理操作的审计日志,确保所有操作都符合安全规范并可追溯 | 记录详细的代理行为日志,进行事件跟踪和行为分析。 |
智能体安全最佳实践
’ fill=‘%23FFFFFF’%3E%3Crect x=‘249’ y=‘126’ width=‘1’ height=‘1’%3E%3C/rect%3E%3C/g%3E%3C/g%3E%3C/svg%3E)
单智能体架构
| 主分类 | 关键措施/子项 | 实施要点与资源 |
|---|---|---|
| 认证与授权 | 实施 OAuth 2.0/OIDC | 基于 OAuth 2.0 实现权限委派和授权,使用带 PKCE 的授权码流程增强安全性,要求用户明确同意,并颁发短期令牌(参考:Auth0 OAuth 2.0 指南)。 |
| 使用托管身份服务 | 利用云服务商身份服务(如 AWS IAM 角色、Azure 托管身份)替代嵌入凭据,避免密钥存储(参考:AWS EC2 IAM 角色文档)。 | |
| 应用基于角色的访问控制 (RBAC) | 定义细粒度的代理功能角色,实施权限矩阵跟踪能力(参考:NIST RBAC 标准)。 | |
| 仅授予最低必要权限 | 仅分配代理任务所需的最小权限集,并定期审计权限分配。 | |
| 区分读写访问权限 | 分离读写权限,默认只读,仅在必要时显式授予写权限(参考:AWS IAM 最佳实践)。 | |
| 考虑即时凭据签发 | 使用临时、限范围、短生命周期的凭据(参考:HashiCorp Vault)。 | |
| 数据保护 | 加密敏感数据 | 对静态和传输中数据使用强加密(TLS 1.2+,AES-256-GCM)(参考:NIST 加密标准)。 |
| 实施数据防泄漏 (DLP) | 部署 DLP 监控敏感信息泄漏,扫描输入/输出中的 PII 和凭证(参考:OpenDLP)。 | |
| 使用数据分类和敏感度标签 | 应用标签分级(公开/内部/机密/受限)控制代理数据访问权限(例如 HIPAA 合规性)(参考:Microsoft 信息保护)。 | |
| 应用数据最小化原则 | 仅收集处理任务必需数据,通过数据流图识别冗余收集(参考:GDPR 数据最小化原则)。 | |
| 代码安全 | 建立自动化测试流水线 | CI/CD 集成安全扫描(SAST, DAST, SCA)(参考:OWASP DevSecOps 指南)。 |
| 进行彻底的代码审查 | 部署前进行自动化和人工审查,使用 AI 安全清单(参考:OWASP 代码审查指南)。 | |
| 监控依赖项 | 持续扫描外部库漏洞并设置警报(参考:GitHub Dependabot)。 | |
| 监控与事件响应 | 记录所有操作并建立基线 | 全面记录代理活动日志,建立行为基线,敏感操作记录思维链(参考:CSA 日志指南)。 |
| 实施实时异常检测 | 使用 ML(如 SIEM 工具)检测异常行为模式(参考:Awesome 异常检测)。 | |
| 设置可疑事件警报 | 配置异常模式、敏感端点访问、请求激增或异常 IP 警报(参考:PagerDuty)。 | |
| 制定事件响应计划 | 制定包含遏制、调查、修复和恢复步骤的详细预案(参考:NIST 事件处理指南)。 | |
| 构建紧急停止开关 | 实现可立即撤销访问权限或停止代理操作的自动/手动开关(参考:Anthropic AI 安全研究)。 | |
| 提示安全 | 实施输入验证 | 使用规则/NLP/多模态过滤及 WAF 规则验证输入,防御恶意模式(参考:LLM 提示注入防御指南)。 |
| 对 AI 输出应用内容过滤 | 筛查 AI 响应中的不当内容,结合模式匹配和 ML 分类器(参考:Perspective API)。 | |
| 强化系统提示 | 将安全策略嵌入基础指令,构建拒绝有害请求的提示(参考:OpenAI 系统消息指南)。 | |
| 净化所有输入 | 清理、规范化输入,移除/转义特殊字符和格式以防止注入(参考:OWASP 输入验证速查表)。 |
多智能体架构(带中心协调器)
| 主分类 | 关键措施/子项 | 实施要点与资源 |
|---|---|---|
| 认证与授权 | 复用单代理认证授权机制 | 沿用单代理系统(4.1.1)的认证与授权控制措施。 |
| 建立控制平面分离 | 清晰分离不同代理功能,采用“用户假设”架构模式强制执行用户权限,为每个代理维护基于最小权限的不同权限集(参考:AWS 控制与数据平面分离)。 | |
| 认证验证所有代理交互 | 确保所有代理间的交互都经过认证和验证(详见通信安全)。 | |
| 限制发现服务范围 | 在代理指令中硬编码已知可信的发现服务器地址,并使用网络及逻辑控制阻止代理与非授权发现服务器通信。 | |
| 协调器安全 | 强化中心协调器API | 为中心协调器API实施强健的身份验证、授权、速率限制、输入验证和详细日志记录(参考:OWASP API安全TOP10)。 |
| 防护控制流劫持与困惑代理问题 | 验证代理响应以防止操控协调器决策,对操作元数据和代理输出实施完整性检查,并通过额外上下文验证和交叉检查防范“困惑代理问题”(参考:MITRE ATLAS,困惑代理问题资料)。 | |
| 代理间通信 | 实施安全通信协议 | 所有代理交互使用强加密协议,并实施双向认证的相互TLS(mTLS)(参考:Mutual TLS (mTLS) 认证)。 |
| 使用标准协议或预定义模式 | 采用JSON-RPC 2.0和标准化事件方法,利用基于模式的通信简化确定性验证并提高一致性(参考:Google A2A)。 | |
| 验证通信代理身份 | 使用基于证书或令牌的身份验证机制验证每个通信代理的身份(参考:JWT 认证最佳实践)。 | |
| 使用安全消息队列系统 | 采用具备安全特性(认证、加密)的消息代理(如RabbitMQ, Kafka, NATS)进行异步通信(参考:RabbitMQ 安全)。 | |
| 部署策略执行点 (PEPs) | 在通信通道中增设安全检查点(中间件或服务代理)以强制执行策略,验证每次交互。 | |
| 应用代理交互速率限制 | 限制代理间请求频率防止滥用,并对失败请求实施指数退避(参考:GitHub API 速率限制)。 | |
| 信任边界 | 应用零信任安全原则 | 在整个架构中贯彻“永不信任,始终验证”原则,无论来源如何都验证每个访问请求(参考:NIST SP 800-207 零信任架构)。 |
| 实施网络分段与代理隔离 | 在系统内创建不同的安全区域,限制代理的互连性以遏制潜在漏洞扩散(参考:NSA 网络分段指南)。 | |
| 使用容器化技术 | 使用Docker等容器技术沙箱化隔离单个代理,限制其对底层OS和系统资源的访问(参考:Docker 安全最佳实践)。 |
多智能体架构(集群)
| 主分类 | 关键措施/子项 | 实施要点与资源 |
|---|---|---|
| 认证与授权 | 复用现有认证授权机制 | 沿用单代理(4.1.1)和中心协调多代理(4.2.1)系统的认证与授权控制措施。 |
| 识别可信代理与操作 | 在代理流程之外定义信任和正确操作标准,限制或禁止集群在无人指导下自主添加新代理。 | |
| 去中心化身份与信任 | 实施去中心化标识符 (DIDs) | 采用 W3C 标准 DIDs 建立代理自托管身份,实现无需中心权威的身份验证(参考:W3C DIDs 规范)。 |
| 使用可验证凭证 (VCs) | 利用 VCs 使代理能证明特定属性,提供能力或授权的安全可验证证明(参考:W3C VCs 数据模型)。 | |
| 创建去中心化信誉系统 | 构建基于代理行为生成信誉评分的系统,并据此做出协作信任决策(参考:OpenCerts 可验证声明框架)。 | |
| 安全的点对点通信 | 选择合适的 P2P 协议 | 根据安全与性能需求选择协议(如 TLS/SSL, DTLS, Noise 协议)(参考:Noise 协议框架)。 |
| 确保加密与身份验证 | 实施强加密保障通信机密性,使用可靠认证验证参与代理身份(参考:NIST SP 800-175B 加密标准指南)。 | |
| 跨架构安全考量 | 设计安全的代理通信 API | 实现带全面输入验证的标准化接口,无论架构如何均应用速率限制和认证(参考:OWASP API 安全 TOP10)。 |
| 持续安全测试 | 定期扫描所有代理架构漏洞,实施自动化与手动安全测试流程(参考:NIST 安全测试指南)。 | |
| 安全监控与威胁检测 | 无论架构如何均实施全面监控,并根据架构特点调整检测策略(参考:MITRE ATT&CK 框架)。 | |
| 安全的代理更新与维护 | 为所有架构实施安全更新机制,部署前验证更新完整性(参考:NIST 安全软件开发框架)。 |
智能体操作能力安全控制
API访问安全控制
| 核心威胁 | 关键措施 | 实施要点 |
|---|---|---|
| T3: 未授权数据访问/泄露 T4, T2: API 滥用 (DoS, 成本超支) T3, T9: 密钥泄露 | 实施最小权限原则 | 使用细粒度 OAuth 作用域或受限 API 密钥仅授予完成任务所需的最小权限(实现参考:Okta, Auth0, Keycloak, AWS API Gateway, Cloud IAM)。 |
| 设置 API 允许列表 | 定义授权域或 URL 路径白名单,通过代理/API 网关/网络策略限制仅连接预批准目标,防止操纵(如 Prompt Injection)。 | |
| 优先使用 API 模板 | 采用模板(如 Jinja2)硬编码固定字段,让 LLM 仅填充预定义参数(需严格模式输出和类型定义),避免不安全或格式错误的 API 调用。 | |
| Web 内容净化与安全策略 | 使用 DOMPurify 等工具净化获取的 web 内容,并实施内容安全策略 (CSP) 进行渲染防护。 |
代码执行安全控制
| 核心威胁 | 关键措施 | 实施要点 |
|---|---|---|
| T11, T3: 任意代码执行 (RCE) T11, T2: 代码注入 T4: 资源耗尽导致 DoS T6: 机密信息泄露 | 强制沙箱隔离 | 使用 OS 级隔离、容器、VM、WebAssembly 或云解决方案隔离执行环境(参考:NVIDIA WASM Sandboxing, LangChain E2B)。 |
| 执行静态代码分析 | 对代理生成代码使用 Bandit (Python)、Semgrep (多语言)、CodeShield (LLM 生成代码) 等工具进行漏洞分析。 | |
| 强制执行资源限制 | 设置严格的 CPU、内存和执行时间限制,所有操作实施超时控制。 | |
| 附加安全措施 | 实施严格文件系统和网络限制,命令白名单,高风险操作需人工审批 (HITL),净化代码输出,执行时进行运行时监控;可能时使用代码签名/验证。 |
数据库执行安全控制
| 核心威胁 | 关键措施 | 实施要点 |
|---|---|---|
| T2: SQL 注入 T3: 未授权数据暴露/修改 T1, T5, T3: RAG 数据投毒/敏感数据检索 | 使用带访问控制的托管向量数据库 | 限制数据摄取匹配访问控制能力,应用数据分类标签强制执行用户权限(参考:Elastic RAG, Pinecone+Clerk, Aserto)。 |
| 实施查询安全措施 | 仅使用参数化/模板查询/ORM;通过最小权限账户(如 SELECT only, RLS/CLS)访问数据库;过滤危险 SQL 关键字;验证所有影响查询的用户输入(优先受控通道)。 | |
| RAG 特定控制 | 实施检索后过滤检查敏感内容 (PII),嵌入向量存储前应用内容验证,限制检索操作速率。 |
Web使用安全控制
| 核心威胁 | 关键措施 | 实施要点 |
|---|---|---|
| T11: 恶意 Web 内容 (XSS, 漏洞利用) T6: 机密信息泄露 T7: 钓鱼/欺骗 T2, T3: 服务器端请求伪造 (SSRF) T3: 访问用户浏览器数据 | 沙箱化浏览器组件 | 在严格受控环境(如独立进程、容器)中运行浏览器组件;避免使用扩展或直接在用户浏览器中操作。 |
| 实施 URL 安全 | 使用白名单 URL 过滤;利用安全 Web 网关 (SWG)/DLP 执行策略;执行目标域名信誉检查;强制 TLS 验证;检测阻止开放重定向/过度跳转(结合 DNS 和 HTTP 过滤)。 | |
| 应用防护措施 | 使用网络分段防止 SSRF 访问内部系统;限制 Web 访问速率防滥用;限制可下载文件类型;处理前使用工具净化内容;检查嵌入/链接内容(如 iframe, JS 注入源)。 | |
| 日志记录与监控 | 记录所有 URL 访问和 HTTP 响应。 |
PC操作安全控制
| 核心威胁 | 关键措施 | 实施要点 |
|---|---|---|
| T3: 未授权文件访问/修改 T11, T3, T2: 任意 OS 命令执行 T3: 横向移动 | 应用严格隔离 | 使用 OS 级沙箱(如 seccomp, AppArmor);以最小权限的受限用户身份运行代理;考虑专用容器/VM 进行强隔离。 |
| 实施访问控制 | 定义严格的 OS 操作和文件路径允许/拒绝列表;酌情使用虚拟文件系统接口;拦截 OS 命令调用以强制执行白名单。 | |
| 限制敏感数据累积 | 沙箱环境应设计为不持久累积数据和会话状态。 | |
| 增强监控与监督 | 记录代理所有 OS 级操作;关键操作考虑人工审批 (HITL);执行前验证命令。 |
操作关键系统安全控制
| 核心威胁 | 关键措施 | 实施要点 |
|---|---|---|
| T2, T3, T6, T7: 灾难性物理后果 T2, T6: 恶意控制注入 T1, T5: 影响决策的虚假数据 | 应用最高级别隔离 | 使用物理隔离(气隙)网络;使用高度分段网络;实施物理安全措施保护关键系统。 |
| 强制执行多因素认证 | 对敏感操作采用外部流程要求 MFA(避免代理参与 MFA 流程或保留特权会话);对每个关键操作强制人工审批 (HITL)(提示需简洁、有效)。 | |
| 实施安全机制 | 默认代理权限为只读监控;使用针对系统安全参数调整的异常检测;遵守工业控制安全标准(如 IEC 62443);确保存在物理互锁和紧急超驰控制。 |
智能体供应链安全
代码安全
| 关键措施 | 实施要点 |
|---|---|
| 第三方库与框架安全 | 应用标准供应链安全实践:SCA扫描 + 第三方版本哈希锁定 + SBOM生成(软件物料清单)。 |
| LLM/代理生成代码安全 | 对代理生成/运行的代码强制沙箱隔离;执行前验证依赖包;高风险代码执行需人工审批(HITL);安装前验证第三方库的许可证和来源。 |
环境与开发安全
| 关键措施 | 实施要点 |
|---|---|
| LLM/逻辑系统安全 | 开发与生产环境使用相同LLM确保可靠性;通过哈希和贡献者验证公共注册表(如Hugging Face)的LLM来源;使用LLM+SCA扫描器检测第三方包漏洞与LLM代码问题。 |
| 版本控制与代码管理 | 对LLM和逻辑系统实施版本控制追踪行为;对提示词和指令进行版本管理以提高可靠性和可审计性;数据变更使用提交ID和哈希记录。 |
| 权限管理 | 禁止代理访问构建/部署自身的代码库或数据源;在代理运行环境外管理数据源权限;通过代码修改IAM/角色权限(需人工审查变更)。 |
代理与工具发现安全
| 关键措施 | 实施要点 |
|---|---|
| 代理凭证 | 通过代理凭证明确信任关系,最小化未验证代理系统的信任;使用去中心化标识符(DIDs)实现代理验证和认证。 |
| 本地与远程注册库隔离 | 本地/远程注册库间设置逻辑或网络屏障防混淆;分离私有/公共代理/数据/操作,禁止跨边界数据共享或操作;使用证书固定等控制确保代理仅连接授权注册库和环境。 |
智能体安全评测基准
静态测试基准
| 工具 | 用途与特点 |
|---|---|
| AgentDojo | 动态评估 LLM 代理在提示注入攻击下的安全性,内置针对性注入攻击,可指示代理执行恶意任务并观测防护效果。 |
| Agentic Radar | 分析代理系统的安全与运行状况,自动映射组件与流程,帮助发现潜在漏洞并提供安全洞察。 |
| AgentSafetyBench | 基准测试 LLM 代理的安全合规性,通过多场景提示或对话检查代理是否生成有害、高风险内容,并评估对提示注入、角色混淆等问题的防御能力。 |
| AgentSecurityBench (ASB) | 红队攻击框架,支持直接/间接提示注入(DPI/IPI)、Plan‑of‑Thought 后门、内存投毒等多种攻击场景,用于系统化评估代理安全。 |
| MAPS | 多语言安全评测基准,将 ASB 等基准翻译成 10 种语言,用于评估 AI 代理在跨语言场景下的安全防御能力。 |
| AgentPoison | 记忆/知识库投毒工具,可向代理的知识库或内存注入恶意实例,并在触发词出现时召回,测试代理对内存污染的抵御能力。 |
| AgentFence | 代理安全红队工具集,聚焦提示注入、角色混淆、系统指令泄露等漏洞,提供多种攻击场景以发现代理弱点。 |
行为测试****基准
- 定义安全目标
- 评估威胁形势
- 研究现有基准寻找针对智能体脆弱性的基准
- 评估基准标准,确保基准覆盖率
- 测试基准的适用性
- 比较不同基准并选择最符合需求的
- 建立持续评估机制
- 参与AI安全社区讨论
智能体部署安全
| 安全领域 | 核心措施与实施要点 |
|---|---|
| 安全管道与恶意代理检测 | 在CI/CD管道集成依赖扫描、代理工具使用静态分析及提示注入动态测试,并辅以代码签名和人工审查确保仅安全代理投产。 |
| 角色容器化/FaaS隔离 | 采用容器化(Docker/K8s)或FaaS(AWS Lambda)实施资源限制/网络分段/临时上下文,隔离单代理入侵影响范围。 |
| API访问控制与网关防护 | 通过API网关强制执行代理认证、参数级授权及速率限制,集中审计工具交互并防御DoS攻击。 |
| 异常行为告警 | 建立工具使用序列与资源消耗基线,实时告警异常操作、逻辑突变或数据访问偏离。 |
| 高风险环境人工监督 | 对关键决策/行为偏离强制HITL审批,采用自适应监督机制动态调整管控强度(参考欧盟AI法案高风险定义)。 |
| 非人类身份管理 | 为代理分配唯一身份并全生命周期管控:安全配置凭证、密钥定期轮换、停用即时注销,杜绝遗留凭证风险。 |
智能体运行安全
| 安全领域 | 核心措施与实施要点 |
|---|---|
| 虚拟机基础加固 | 使用最小化镜像(distroless/Alpine),启用Secure Boot/TPM加密,关闭非必要服务,配置防火墙规则,自动化补丁更新。 |
| 网络隔离 | 将VM置于私有子网/VPC,通过服务网格/API网关管控代理间通信,限制直接互联网访问并监控例外流量。 |
| 运行时沙箱隔离 | 采用容器/命名空间(gVisor/Firecracker)隔离代理进程,使用AppArmor/seccomp限制系统调用,挂载只读文件系统。 |
| 能力范围控制 | 通过AGNTCY层声明式管控工具权限(如禁用shellExec),引入会话级能力令牌,用JSON-RPC包装器(如MCP)强制边界。 |
| 内存与工具安全 | 加密内存状态,会话结束自动清除内存/向量数据库,运行时验证工具输入输出,动态策略引擎(如AGNTCY)控制API调用权限。 |
| 审计与异常检测 | 完整记录代理操作(含时间戳/代理ID/载荷哈希),安全存储审计日志;基于策略引擎/LLM检测异常工具调用/内存暴涨。 |
| 身份与会话管理 | 采用JWT/mTLS/HMAC实现代理会话认证,通过MCP分配唯一临时会话上下文。 |
| 访问控制 | 结合RBAC(代理角色)与能力令牌实施动态授权(如研究代理仅限文档搜索/摘要操作)。 |
| 云环境加固 | 限制元数据服务访问(AWS IMDSv2),配置VM级最小权限IAM角色,启用机密计算(AMD SEV/Intel SGX)。 |